Why Solving for Interoperability Is a Huge Challenge—and Opportunity—in Supply Chain
Brad Svrluga and Zach Fredericks on why this category of supply chain innovation holds venture-scale promise.






By Wyatt Bramhall, Zach Fredericks, and Brad Svrluga
Subscribe to future editions of the Supply Chain newsletter here.
If you’ve ever worked in a logistics or manufacturing centric role, you know how much of a hassle it is to integrate new products and share data with customers and vendors. You’ve lived in a world of inbox anxiety and waited for painstakingly slow EDI integrations to get built in exchange for an arm and a leg. The brave entrepreneurs who have tried to bring new supply chain software to market also know the pain of integrating with legacy supply chain systems, and many of them have failed trying.
This challenge will only become more acute given the macro forces driving change in supply chains. As companies work towards building more durable supply chains, they will have to add more workflow software to their supply chain stack, work with more supply chain vendors, and move a lot more data. Whether you are a software startup looking to build on TMS data or a logistics company looking to build EDI integrations with customers, we think that supply chain interoperability is going to continue to be a huge but essential challenge. Solving it will be critical to meeting global demands for supply chain durability.
We've seen plenty of startups building unified APIs for specific pieces of supply chain data. These opportunities have all been difficult for us to get excited about because they are either too niche, not defensible, or heavily service-oriented. That said, we know that building these integrations is a huge pain point for software players in the supply chain stack and vendors and customers in supply chain orgs trying to integrate with each other. In this piece we’ll break down the different integrations that are needed in the supply chain, the players that exist in the space today, and where we see opportunities for new, venture scale businesses.
Complexity of supply chain data sharing
There is a flood of software adoption and new partnerships being formed in supply chain organizations, but a real lack of infrastructure to stitch all these systems together. Other industries have seen similar problems in their software maturity curves and many a unicorn has been born out of solving those problems. Plaid famously aggregated consumer banking data from thousands of banks and made it available through a universal API, which enabled the birth and success of countless consumer fintech applications. These applications would have otherwise died spending resources on integrations, each of which would only give them access to slivers of their potential customer base.
The data sharing needs of a modern supply chain include a huge number of participants, each with their own tech stack. A large enterprise will have horizontal ERPs (Oracle, SAP, Netsuite, etc) and data warehouses (Azure, AWS, Snowflake, etc) that need to connect to their core supply chain management systems (TMS, WMS, etc). They will also have additional supply chain analytics and execution applications (Lyric, O9, GoodShip, Loop, Parade, Project44, etc) that need to integrate with their core systems. Then on top of that they need to connect with all their suppliers, customers, transportation vendors, and more.

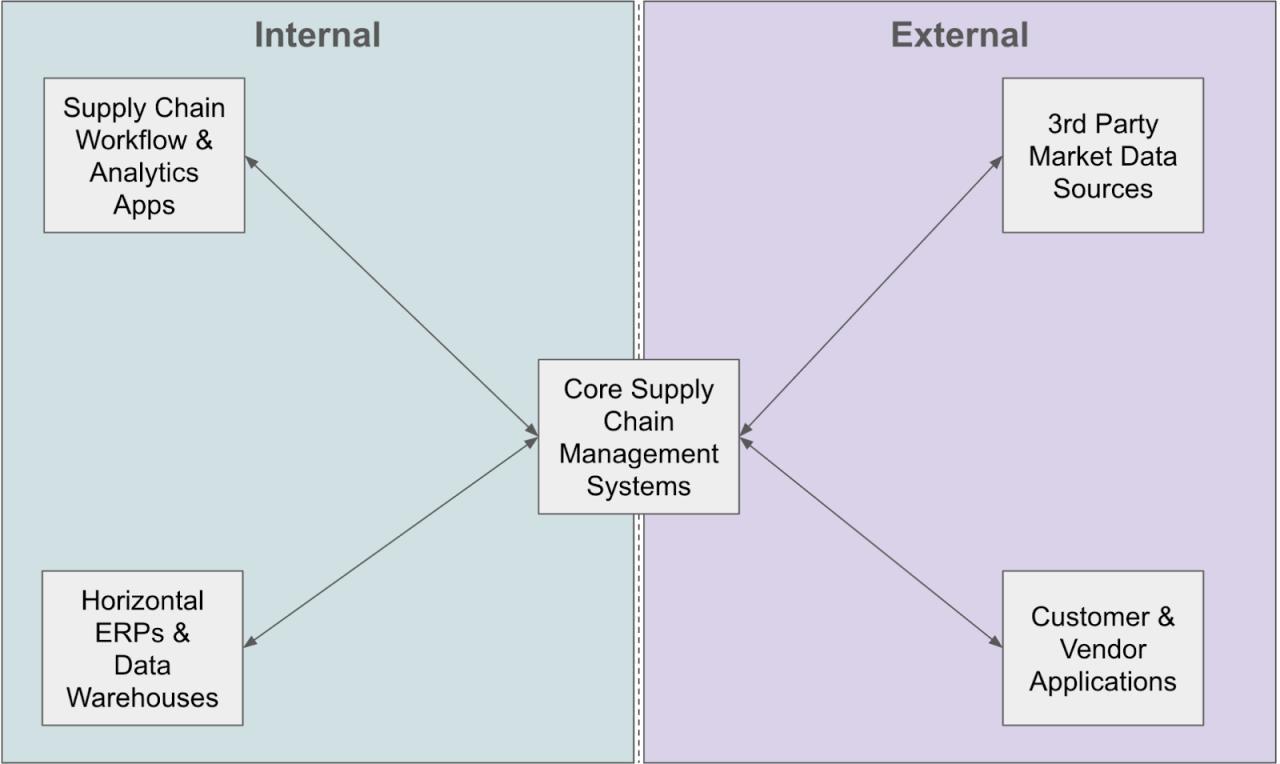
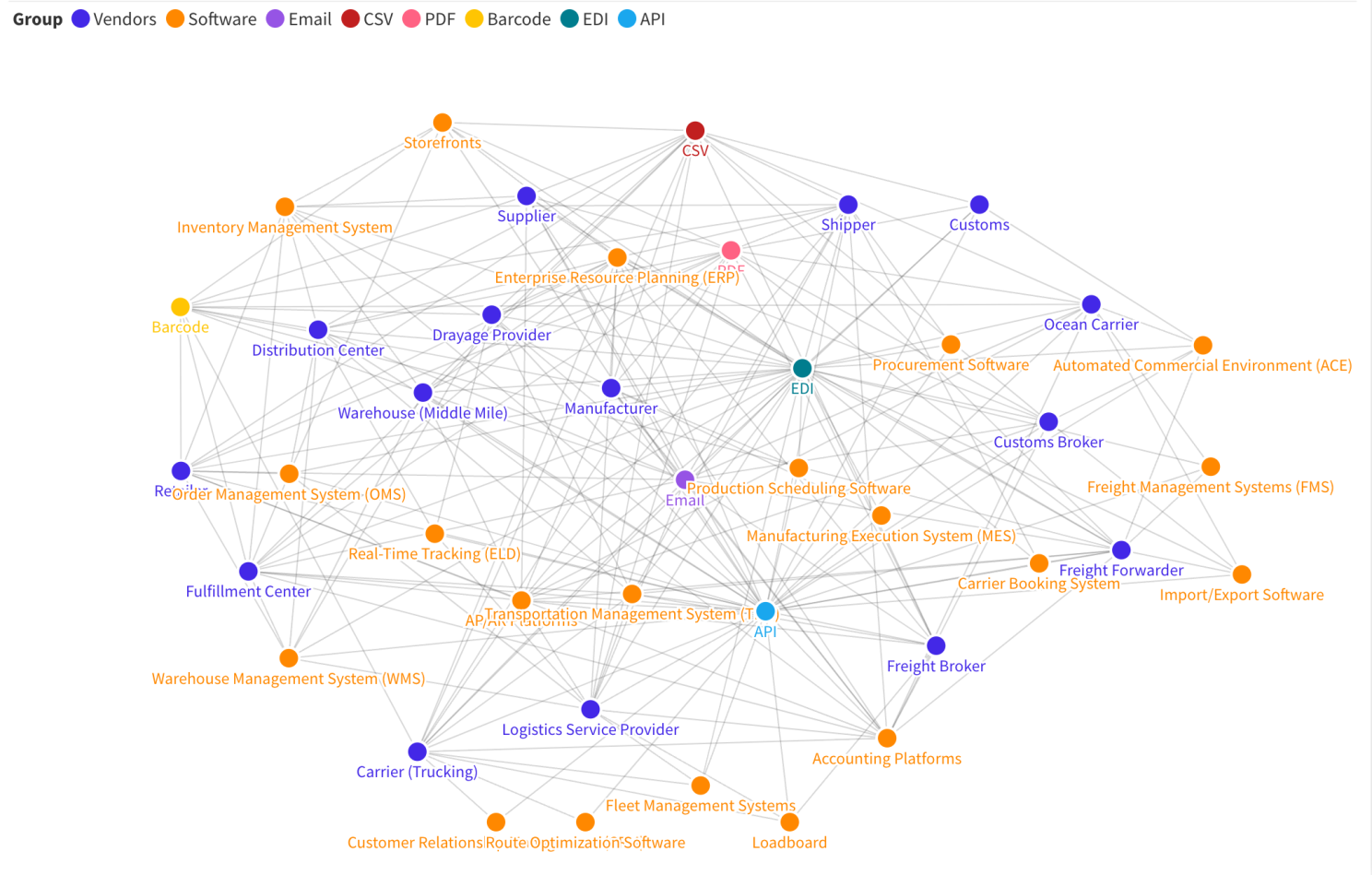
In the graphic above, we’ve laid out a very simple illustration of how various nodes of the supply chain system must come together. In reality, though, with all the different tech stacks at play, the data sharing needs look much more like the brutally complex, spiderweb system here.
An interactive version of the image above can be found here.

How integrations are getting done today
There are a lot of solutions in the market today that address supply chain infrastructure. Most of the incumbents in this world are integration service providers that come in two main types: turnkey development tailored for businesses and iPaaS (Integration Platform as a Service). Both primarily target business teams as their core users, handling internal and external business logic to establish data mappings, which are then passed on to engineers. These solutions are beneficial for teams with limited engineering resources and therefore common in transportation and manufacturing spaces. Their effectiveness, of course, relies heavily on customer service. Those who have executed integrations through this method can confirm the considerable time investment involved, often posing more of a project management challenge than a technical solution.

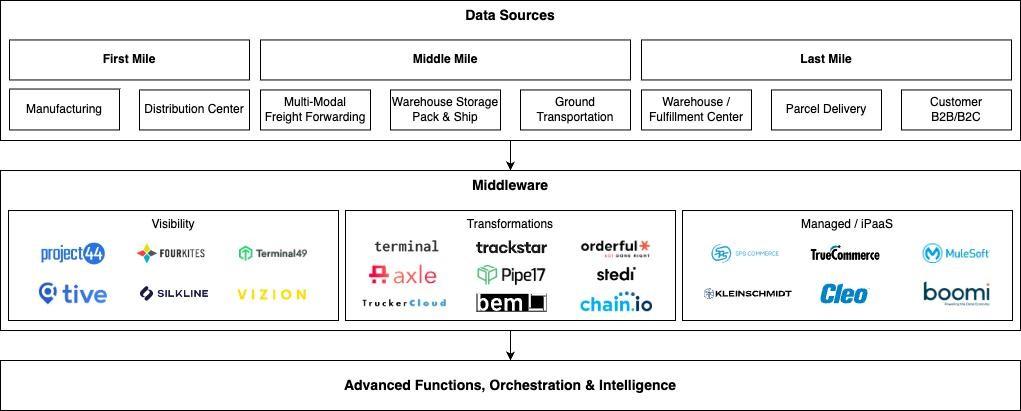
Startups are adopting an alternative approach by developing API-first solutions tailored for engineers. These solutions are typically categorized into two types: visibility aggregators and vertical-specific transformations.
Visibility aggregators, like Project44 and FourKites, consolidate data from various third-party sources to construct comprehensive datasets that companies can utilize to track the location and transport status of their goods. On the other hand, vertical-specific data transformers concentrate on standardizing data within specific industries, such as ocean freight or direct-to-consumer fulfillment, offering a unified access point to multiple platforms, allowing companies to easily transact across many platforms in the same way. We’ve noticed the first wave of data transformation startups in this space have still required a significant amount of professional service support to scale. That said, there is a new crop of universal API for “x” companies that have raised recently that stand a good chance of being lower touch and developer-facing. Companies in this batch typically focus on smaller opportunities when getting started and have frequently struggled to find ways to expand their footprint across the supply chain stack.
Where opportunities exist
We're trying to look at the opportunity more holistically, by seeing what consistent data is needed by all players across the supply chain in each of their stacks. We think the basics of a great universal connector business is likely there. This confidence is born of three reasons: 1) there’s a big market of customers who need this data, 2) a lot of systems that need to be connected leaving room for a first-mover moat, and 3) there are consistent data structures needed across each of these systems. We believe that to achieve venture scale, you must set the standard for all data flows, rather than just being a piece of the puzzle.
We believe there are solutions that transcend the multitude of file formats and custom integrations required to manage a supply chain tech stack in today's landscape. Despite the complexity of systems and vendors, the data needs are fairly consistent. Supply chain data centers around quotes, orders, order statuses, invoices, and partner information. This is of course a simplification of all the different end points that would be needed to build a universal integration platform for supply chain, but that consistency tells us that it’s actually possible for someone to aggregate data from a lot of systems and deliver value to a lot of customers. The harder part will likely be building all of these integrations and deciding which systems and customers to target. We are convinced that there is a substantial opportunity to harness generative AI to significantly diminish the overhead associated with building integrations. We’re less confident on which systems and customers to target. We have some ideas, but would love to hear yours. If building at the intersection of data infrastructure and supply chain gets you excited (how could it not??), don’t be a stranger!